Architecture Overview
Overview
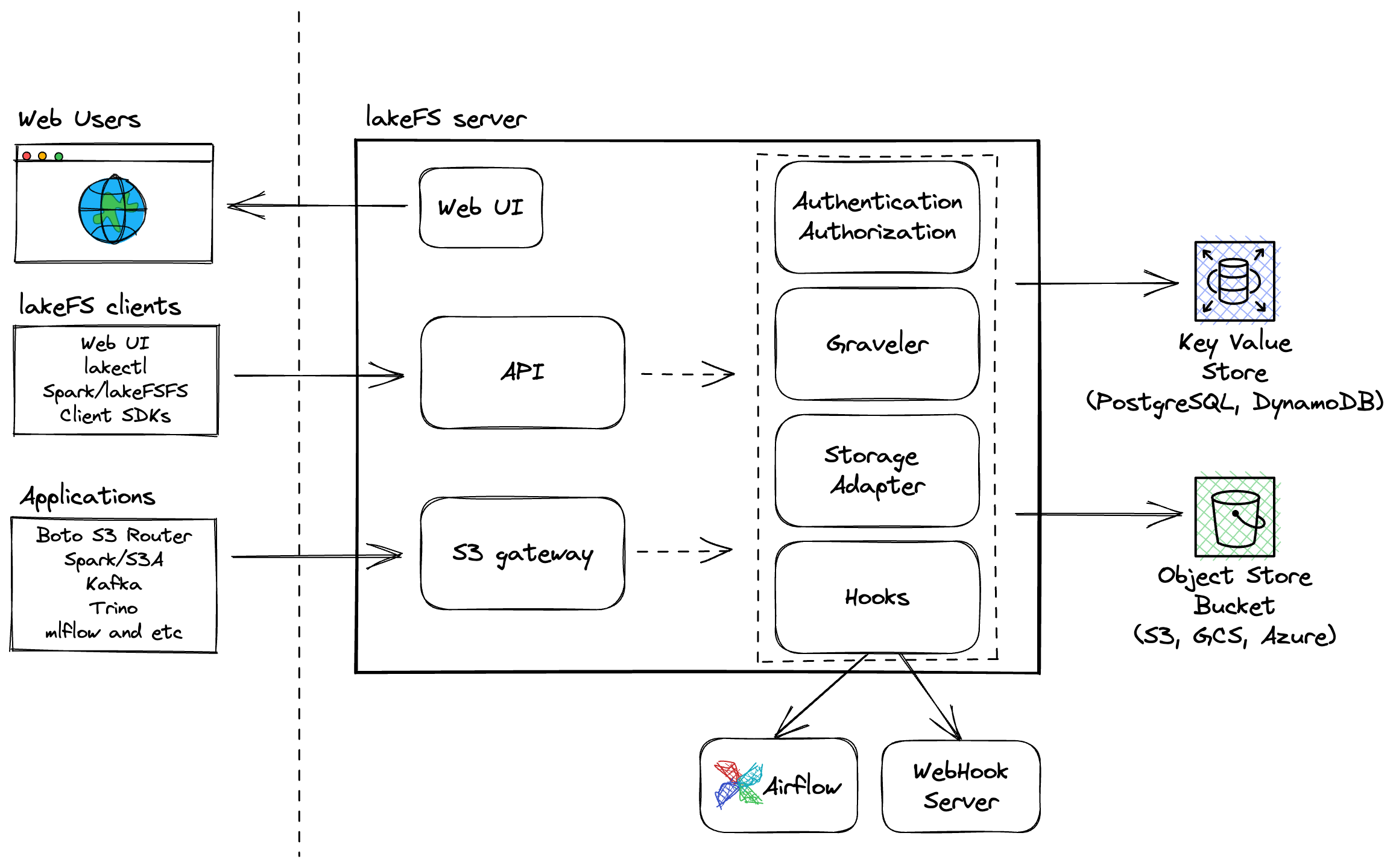
lakeFS is distributed as a single binary encapsulating several logical services:
The server itself is stateless, meaning you can easily add more instances to handle a bigger load.
The following underlying object stores (or any S3-compatible store) can be used by lakeFS to store data:
- Google Cloud Storage (Prepare Your GCS Bucket)
- Azure Blob Storage (Prepare Your Blob Storage Container)
- AWS S3 (Prepare Your AWS S3 Bucket)
- MinIO (Using lakeFS with MinIO)
- Ceph
In additional a Key Value storage is used for storing metadata:
Instructions of how to deploy such database on AWS can be found here.
Additional information on the data format can be found in Versioning internals.
Ways to deploy lakeFS
lakeFS releases include binaries for common operating systems, a containerized option or a Helm chart. Check out our guides for running lakeFS on K8S, ECS, Google Compute Engine and more.
Load Balancing
Accessing lakeFS is done using HTTP. lakeFS exposes a frontend UI, an OpenAPI server, as well as an S3-compatible service (see S3 Gateway below). lakeFS uses a single port that serves all three endpoints, so for most use cases a single load balancer pointing to lakeFS server(s) would do.
lakeFS Components
S3 Gateway
The S3 Gateway implements lakeFS’s compatibility with S3. It implements a compatible subset of the S3 API to ensure most data systems can use lakeFS as a drop-in replacement for S3.
See the S3 API Reference section for information on supported API operations.
OpenAPI Server
The Swagger (OpenAPI) server exposes the full set of lakeFS operations (see Reference). This includes basic CRUD operations against repositories and objects, as well as versioning related operations such as branching, merging, committing, and reverting changes to data.
Storage Adapter
The Storage Adapter is an abstraction layer for communicating with any underlying object store. Its implementations allow compatibility with many types of underlying storage such as S3, GCS, Azure Blob Storage, or non-production usages such as the local storage adapter.
See the roadmap for information on the future plans for storage compatibility.
Graveler
The Graveler handles lakeFS versioning by translating lakeFS addresses to the actual stored objects. To learn about the data model used to store lakeFS metadata, see the data model section.
Authentication & Authorization Service
The Auth service handles the creation, management, and validation of user credentials and RBAC policies.
The credential scheme, along with the request signing logic, are compatible with AWS IAM (both SIGv2 and SIGv4).
Currently, the Auth service manages its own database of users and credentials and doesn’t use IAM in any way.
Hooks Engine
The Hooks Engine enables CI/CD for data by triggering user defined Actions that will run during commit/merge.
UI
The UI layer is a simple browser-based client that uses the OpenAPI server. It allows management, exploration, and data access to repositories, branches, commits and objects in the system.
Applications
As a rule of thumb, lakeFS supports any S3-compatible application. This means that many common data applications work with lakeFS out-of-the-box. Check out our integrations to learn more.
lakeFS Clients
Some data applications benefit from deeper integrations with lakeFS to support different use cases or enhanced functionality provided by lakeFS clients.
OpenAPI Generated SDKs
OpenAPI specification can be used to generate lakeFS clients for many programming languages. For example, the Python lakefs-client or the Java client are published with every new lakeFS release.
lakectl
lakectl is a CLI tool that enables lakeFS operations using the lakeFS API from your preferred terminal.
Spark Metadata Client
The lakeFS Spark Metadata Client makes it easy to perform operations related to lakeFS metadata, at scale. Examples include garbage collection or exporting data from lakeFS.
lakeFS Hadoop FileSystem
Thanks to the S3 Gateway, it’s possible to interact with lakeFS using Hadoop’s S3AFIleSystem, but due to limitations of the S3 API, doing so requires reading and writing data objects through the lakeFS server. Using lakeFSFileSystem increases Spark ETL jobs performance by executing the metadata operations on the lakeFS server, and all data operations directly through the same underlying object store that lakeFS uses.