Garbage Collection
By default, lakeFS keeps all your objects forever. This allows you to travel back in time to previous versions of your data. However, sometimes you may want to hard-delete your objects - namely, delete them from the underlying storage. Reasons for this include cost-reduction and privacy policies.
Garbage collection rules in lakeFS define for how long to retain objects after they have been deleted (see more information below).
lakeFS provides a Spark program to hard-delete objects that have been deleted and whose retention period has ended according to the GC rules.
The GC job does not remove any commits: you will still be able to use commits containing hard-deleted objects,
but trying to read these objects from lakeFS will result in a 410 Gone HTTP status.
Note At this point, lakeFS supports Garbage Collection only on S3 and Azure. We have concrete plans to extend the support to GCP.
- Understanding Garbage Collection
- Configuring GC rules
- Running the GC job
- Considerations
- GC backup and restore
Understanding Garbage Collection
For every branch, the GC job retains deletes objects for the number of days defined for the branch. In the absence of a branch-specific rule, the default rule for the repository is used. If an object is present in more than one branch ancestry, it’s retained according to the rule with the largest number of days between those branches. That is, it’s hard-deleted only after the retention period has ended for all relevant branches.
Example GC rules for a repository:
{
"default_retention_days": 14,
"branches": [
{"branch_id": "main", "retention_days": 21},
{"branch_id": "dev", "retention_days": 7}
]
}
In the above example, objects are retained for 14 days after deletion by default. However, if they are present in the branch main, they are retained for 21 days.
Objects present in the dev branch (but not in any other branch) are retained for 7 days after they are deleted.
What gets collected
Because each object in lakeFS may be accessible from multiple branches, it might not be obvious which objects will be considered garbage and collected.
Garbage collection is configured by specifying the number of days to retain objects on each branch. If a branch is configured to retain objects for a given number of days, any object that was accessible from the HEAD of a branch in that past number of days will be retained.
The garbage collection process proceeds in three main phases:
-
Discover which commits will retain their objects. For every branch, the garbage collection job looks at the HEAD of the branch that many days ago; every commit at or since that HEAD must be retained.
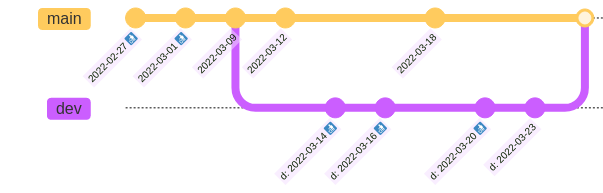
Continuing the example, branch
mainretains for 21 days and branchdevfor 7. When running GC on 2022-03-31:- 7 days ago, on 2022-03-24 the head of branch
devwasd: 2022-03-23. So, that commit is retained (along with all more recent commits ondev) but all older commitsd: *will be collected. - 21 days ago, on 2022-03-10, the head of branch
mainwas2022-03-09. So that commit is retained (along with all more recent commits onmain) but commits2022-02-27and2022-03-01will be collected.
- 7 days ago, on 2022-03-24 the head of branch
-
Discover which objects need to be garbage collected. Hold (only) objects accessible on some retained commits.
In the example, all objects of commit
2022-03-12, for instance, are retained. This includes objects added in previous commits. However, objects added in commitd: 2022-03-14which were overwritten or deleted in commitd: 2022-03-20are not visible in any retained commit and will be garbage collected. -
Garbage collect those objects by deleting them. The data of any deleted object will no longer be accessible. lakeFS retains all metadata about the object, but attempting to read it via the lakeFS API or the S3 gateway will return HTTP status 410 (“Gone”).
What does not get collected
Some objects will not be collected regardless of configured GC rules:
- Any object that is accessible from any branch’s HEAD.
- Any object that was uploaded but never committed cannot be collected. See #1933 for more details.
- Objects stored outside the repository’s storage namespace. For example, objects imported using the lakeFS import UI are not collected.
Configuring GC rules
Using lakectl
Use the lakectl CLI to define the GC rules:
cat <<EOT >> example_repo_gc_rules.json
{
"default_retention_days": 14,
"branches": [
{"branch_id": "main", "retention_days": 21},
{"branch_id": "dev", "retention_days": 7}
]
}
EOT
lakectl gc set-config lakefs://example-repo -f example_repo_gc_rules.json
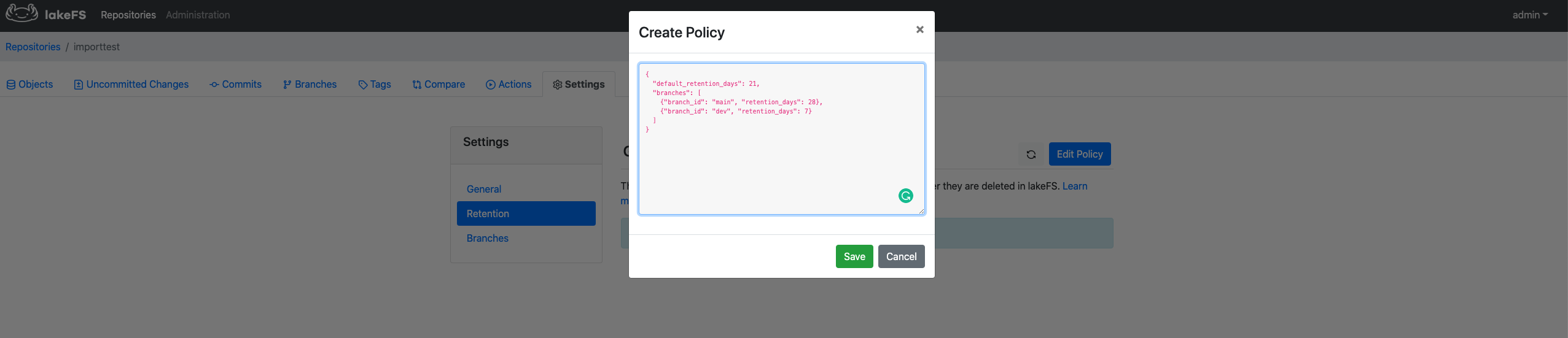
From the lakeFS UI
- Navigate to the main page of your repository.
- Go to Settings -> Retention.
- Click Edit policy and paste your GC rule into the text box as a JSON.
- Save your changes.
Running the GC job
The GC job is a Spark program that can be run using spark-submit (or using your preferred method of running Spark programs).
The job will hard-delete objects that were deleted and whose retention period has ended according to the GC rules.
First, you’ll have to download the lakeFS Spark client Uber-jar. The Uber-jar can be found on a public S3 location:
For Spark 2.4.7:
http://treeverse-clients-us-east.s3-website-us-east-1.amazonaws.com/lakefs-spark-client-247/${CLIENT_VERSION}/lakefs-spark-client-247-assembly-${CLIENT_VERSION}.jar
For Spark 3.0.1:
http://treeverse-clients-us-east.s3-website-us-east-1.amazonaws.com/lakefs-spark-client-301/${CLIENT_VERSION}/lakefs-spark-client-301-assembly-${CLIENT_VERSION}.jar
CLIENT_VERSIONs for Spark 2.4.7 can be found here, and for Spark 3.0.1 they can be found here.
Running instructions:
You should specify the Uber-jar path instead of <APPLICATION-JAR-PATH> and run the following command to make the garbage collector start running:
spark-submit --class io.treeverse.clients.GarbageCollector \
--packages org.apache.hadoop:hadoop-aws:2.7.7 \
-c spark.hadoop.lakefs.api.url=https://lakefs.example.com:8000/api/v1 \
-c spark.hadoop.lakefs.api.access_key=<LAKEFS_ACCESS_KEY> \
-c spark.hadoop.lakefs.api.secret_key=<LAKEFS_SECRET_KEY> \
-c spark.hadoop.fs.s3a.access.key=<S3_ACCESS_KEY> \
-c spark.hadoop.fs.s3a.secret.key=<S3_SECRET_KEY> \
<APPLICATION-JAR-PATH> \
example-repo us-east-1
You should run the following command to make the garbage collector start running:
spark-submit --class io.treeverse.clients.GarbageCollector \
--packages org.apache.hadoop:hadoop-aws:3.2.1 \
-c spark.hadoop.lakefs.api.url=https://lakefs.example.com:8000/api/v1 \
-c spark.hadoop.lakefs.api.access_key=<LAKEFS_ACCESS_KEY> \
-c spark.hadoop.lakefs.api.secret_key=<LAKEFS_SECRET_KEY> \
-c spark.hadoop.fs.azure.account.key.<AZURE_STORAGE_ACCOUNT>.dfs.core.windows.net=<AZURE_STORAGE_ACCESS_KEY> \
s3://treeverse-clients-us-east/lakefs-spark-client-312-hadoop3/0.5.1/lakefs-spark-client-312-hadoop3-assembly-0.5.1.jar \
example-repo
Notes:
- To run GC on Azure, use
lakefs-spark-client-312-hadoop3only. This client is compiled for Spark 3.1.2 with Hadoop 3.2.1, but may work with other Spark versions and higher Hadoop versions. Specifically, this client was tested on Databricks runtime DBR 11.0 (Spark 3.3.0, 3.3.2). - GC on Azure is supported from Spark client version >= v0.2.0.
- In case you don’t have
hadoop-azurepackage as part of your environment, you should add the package to your spark-submit with--packages org.apache.hadoop:hadoop-azure:3.2.1 - For GC to work on Azure blob, soft delete should be disabled.
The list of expired objects is written in Parquet format in the storage
namespace of the bucket under _lakefs/retention/gc/addresses/mark_id=MARK_ID, where MARK_ID identifies the run.
Note: if you are running lakeFS Spark client of version < v0.4.0, this file is located under _lakefs/retention/gc/addresses/run_id=RUN_ID,
where RUN_ID identifies the run.
GC job options
By default, GC first creates a list of expired objects according to your retention rules and then hard-deletes those objects. However, you can use GC options to break the GC job down into two stages:
- Mark stage: GC will mark the expired objects to hard-delete, without deleting them.
- Sweep stage: GC will hard-delete objects marked by a previous mark-only GC run.
By breaking GC into these stages, you can pause and create a backup of the objects that GC is about to sweep and later restore them. You can use the GC backup and restore utility to do that.
Mark only mode
To make GC run the mark stage only, add the following properties to your spark-submit command:
spark.hadoop.lakefs.gc.do_sweep=false
spark.hadoop.lakefs.gc.mark_id=<MARK_ID> # Replace <MARK_ID> with your own identification string. This MARK_ID will enable you to start a sweep (actual deletion) run later
Running in mark only mode, GC will write the addresses of the expired objects to delete to the following location: STORAGE_NAMESPACE/_lakefs/retention/gc/addresses/mark_id=<MARK_ID>/ as a parquet.
Notes:
- Mark only mode is only available from v0.4.0 of lakeFS Spark client.
- The
spark.hadoop.lakefs.debug.gc.no_deleteproperty has been deprecated with v0.4.0.
Sweep only mode
To make GC run the sweep stage only, add the following properties to your spark-submit command:
spark.hadoop.lakefs.gc.do_mark=false
spark.hadoop.lakefs.gc.mark_id=<MARK_ID> # Replace <MARK_ID> with the identifier you used on a previous mark-only run
Running in sweep only mode, GC will hard-delete the expired objects marked by a mark-only run and listed in: STORAGE_NAMESPACE/_lakefs/retention/gc/addresses/mark_id=<MARK_ID>/.
Note: Mark only mode is only available from v0.4.0 of lakeFS Spark client.
Performance
Garbage collection reads many commits. It uses Spark to spread the load of reading the contents of all of these commits. For very large jobs running on very large clusters, you may want to tweak this load. To do this:
- Add
-c spark.hadoop.lakefs.gc.range.num_partitions=RANGE_PARTITIONS(default 50) to spread the initial load of reading commits across more Spark executors. - Add
-c spark.hadoop.lakefs.gc.address.num_partitions=RANGE_PARTITIONS(default 200) to spread the load of reading all objects included in a commit across more Spark executors.
Normally this should not be needed.
Networking
Garbage collection communicates with the lakeFS server. Very large repositories may require increasing a read timeout. If you run into timeout errors during communication from the Spark job to lakefs consider increasing these timeouts:
- Add
-c spark.hadoop.lakefs.api.read.timeout_seconds=TIMEOUT_IN_SECONDS(default 10) to allow lakeFS more time to respond to requests. - Add
-c spark.hadoop.lakefs.api.connection.timeout_seconds=TIMEOUT_IN_SECONDS(default 10) to wait longer for lakeFS to accept connections.
Considerations
-
In order for an object to be hard-deleted, it must be deleted from all branches. You should remove stale branches to prevent them from retaining old objects. For example, consider a branch that has been merged to
mainand has become stale. An object which is later deleted frommainwill always be present in the stale branch, preventing it from being hard-deleted. -
lakeFS will never delete objects outside your repository’s storage namespace. In particular, objects that were imported using
lakectl ingestorUI Import Wizardwill not be affected by GC jobs. -
In cases where deleted objects are brought back to life while a GC job is running, said objects may or may not be deleted. Such actions include:
- Reverting a commit in which a file was deleted.
- Branching out from an old commit.
- Expanding the retention period of a branch.
- Creating a branch from an existing branch, where the new branch has a longer retention period.
GC backup and restore
GC was created to hard-delete objects from your underlying objects store according to your retention rules. However, when you start using the feature you may want to first gain confidence in the decisions GC makes. The GC backup and restore utility helps you do that.
This utility is a Spark application that uses distCp under the hood to copy objects marked by GC as expired from one location to another.
Use-cases:
- Backup: copy expired objects from your repository’s storage namespace to an external location before running GC in sweep only mode.
- Restore: copy objects that were hard-deleted by GC from an external location you used for saving your backup into your repository’s storage namespace.
Job options
- This will only work with Hadoop versions > 3.1.3, and so require a Hadoop 3 client.
- Note that the utility is not fast due to distcp performance limitations. You may prefer backup your whole storage namespace with AzCopy / aws cp / rclone.
Running GC backup and restore
You can run GC backup and restore using spark-submit or using your preferred method of running Spark programs.
Currently, GC backup and restore is available for Spark 3.1.2 and 3.2.1, but it may work for other versions.
First, download the lakeFS Spark client Uber-jar. The Uber-jar can be found on a public S3 location:
http://treeverse-clients-us-east.s3-website-us-east-1.amazonaws.com/lakefs-spark-client-312-hadoop3/${CLIENT_VERSION}/lakefs-spark-client-312-hadoop3-assembly-${CLIENT_VERSION}.jar
Note GC backup and restore is available from version 0.5.1 of lakeFS Spark client.
Running instructions:
Backup
You should specify the Uber-jar path instead of <APPLICATION-JAR-PATH>
Program arguments:
- location of expired objects list: the path of an expired objects parquet created by a mark-only GC run. given a
MARK_IDused for a mark-only run this file is located underSTORAGE_NAMESPACE/_lakefs/retention/gc/addresses/mark_id=<MARK_ID>/. - storage namespace: The storage namespace of the lakeFS repository you are running GC for. The storage namespace includes the data you are backing up.
- external location for backup: A storage location outside your lakeFS storage namespace into which you want to save the backup.
- storage type: s3
To start the backup process, run:
spark-submit --class io.treeverse.clients.GCBackupAndRestore \
-c spark.hadoop.fs.s3a.access.key=<AWS_ACCESS_KEY> \
-c spark.hadoop.fs.s3a.secret.key=<AWS_SECRET_KEY> \
<APPLICATION-JAR-PATH> \
expired-objects-list-location storage-namespace backup-external-location s3
You should specify the Uber-jar path instead of <APPLICATION-JAR-PATH>
Program arguments:
- location of expired objects list: the path of an expired objects parquet created by a mark-only GC run. given a
MARK_IDused for a mark-only run this file is located underSTORAGE_NAMESPACE/_lakefs/retention/gc/addresses/mark_id=<MARK_ID>/. - storage namespace: The storage namespace of the lakeFS repository you are running GC for. The storage namespace includes the data you are backing up.
- external location for backup: A storage location outside your lakeFS storage namespace into which you want to save the backup.
- storage type: s3
To start the backup process, run:
spark-submit --class io.treeverse.clients.GCBackupAndRestore \
-c spark.hadoop.fs.azure.account.key.<AZURE_STORAGE_ACCOUNT>.dfs.core.windows.net=<AZURE_STORAGE_ACCESS_KEY> \
<APPLICATION-JAR-PATH> \
expired-objects-list-location storage-namespace backup-external-location azure
Restore
You should specify the Uber-jar path instead of <APPLICATION-JAR-PATH>
Program arguments:
- location of objects to restore list: the path for a list of object that were hard-deleted by a sweep-only GC run. given a
MARK_IDused for a sweep only run the file is located underSTORAGE_NAMESPACE/_lakefs/retention/gc/addresses/mark_id=<MARK_ID>/. - external location to restore from: A storage location outside your lakeFS storage namespace you used for backup.
- storage namespace: The storage namespace of the lakeFS repository you previously ran GC for.
- storage type: s3
To start the restore process, run:
spark-submit --class io.treeverse.clients.GCBackupAndRestore \
--packages org.apache.hadoop:hadoop-aws:2.7.7 \
-c spark.hadoop.fs.s3a.access.key=<AWS_ACCESS_KEY> \
-c spark.hadoop.fs.s3a.secret.key=<AWS_SECRET_KEY> \
<APPLICATION-JAR-PATH> \
objects-to-restore-list-location backup-external-location storage-namespace s3
You should specify the Uber-jar path instead of <APPLICATION-JAR-PATH>
Program arguments:
- location of objects to restore list: the path for a list of object that were hard-deleted by a sweep-only GC run. given a
MARK_IDused for a sweep only run the file is located underSTORAGE_NAMESPACE/_lakefs/retention/gc/addresses/mark_id=<MARK_ID>/. - external location to restore from: A storage location outside your lakeFS storage namespace you used for backup.
- storage namespace: The storage namespace of the lakeFS repository you previously ran GC for.
- storage type: azure
To start the restore process, run:
spark-submit --class io.treeverse.clients.GCBackupAndRestore \
--packages org.apache.hadoop:hadoop-aws:2.7.7 \
-c spark.hadoop.fs.azure.account.key.<AZURE_STORAGE_ACCOUNT>.dfs.core.windows.net=<AZURE_STORAGE_ACCESS_KEY> \
<APPLICATION-JAR-PATH> \
objects-to-restore-list-location backup-external-location storage-namespace azure