During Deployment
Every day we introduce new data to the lake. And even if the code and infra doesn’t change, the data might, and those changes introduce potential quality issues. This is one of the complexities of a data product; the data we consume changes over the course of a month, a week, day, hour, or even minute-to-minute.
Examples of changes to data that may occur:
- A client-side bug in the data collection of website events
- A new Android version that interferes with the collecting events from your App
- COVID-19 abrupt impact on consumers’ behavior, and its effect on the accuracy of ML models.
- During a change to Salesforce interface, the validation requirement from a certain field had been lost
lakeFS enable CI/CD-inspired workflows to help validate expectations and assumptions about the data before it goes live in production or lands in the data environment.
Example 1: Data update safety
Continuous deployment of existing data we expect to consume, flowing from ingest-pipelines into the lake. We merge data from an ingest branch (“events-data”), which allows us to create tests using data analysis tools or data quality services (e.g. Great Expectations, Monte Carlo) to ensure reliability of the data we merge to the main branch. Since merge is atomic, no performance issue will be introduced by using lakeFS, but your main branch will only include quality data.
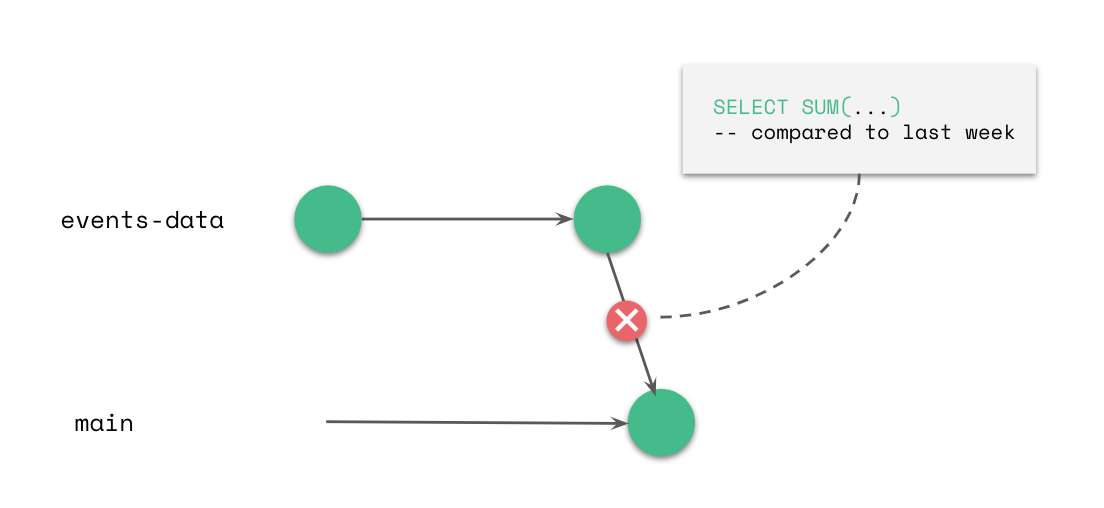
Each merge to the main branch creates a new commit on the main branch, which serves as a new version of the data. This allows us to easily revert to previous states of the data if a newer change introduces data issues.
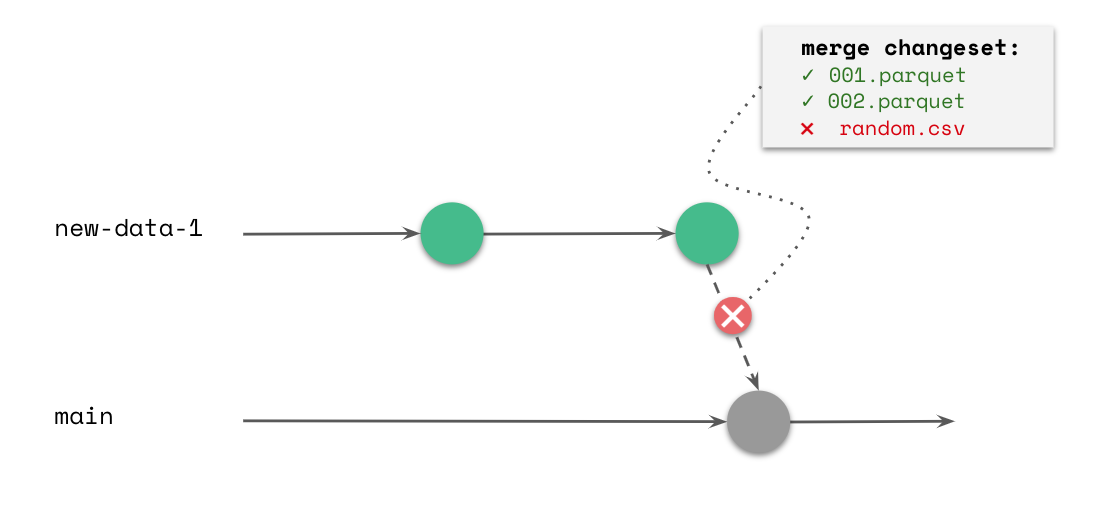
Example 2: Test - Validate new data
Examples of common validation checks enforced in organizations:
- No user_* columns except under /private/…
- Only
(*.parquet | *.orc | _delta_log/*.json)files allowed - Under /production, only backward-compatible schema changes are allowed
- New tables on main must be registered in our metadata repository first, with owner and SLA
lakeFS will assist in enforcing best practices by giving you a designated branch to ingest new data (“new-data-1” in the drawing). . You may run automated tests to validate predefined best practices as pre-merge hooks. If the validation passes, the new data will be automatically and atomically merged to the main branch. However, if the validation fails, you will be alerted and the new data will not be exposed to consumers.
By using this branching model and implementing best practices as pre merge hooks, you ensure the main lake is never compromised.