In Test
As part of our routine work with data we develop new code, improve and upgrade old code, upgrade infrastructures, and test new technologies. lakeFS enables a safe test environment on your data lake without the need to copy or mock data, work on the pipelines or involve DevOps.
Creating a branch provides you an isolated environment with a snapshot of your repository (any part of your data lake you chose to manage on lakeFS). While working on your own branch in isolation, all other data users will be looking at the repository’s main branch. They can’t see your changes, and you don’t see changes to main done after you created the branch.
No worries, no data duplication is done, it’s all metadata management behind the scenes. Let’s look at 3 examples of a test environment and their branching models.
Example 1: Upgrading Spark and using Reset action
You installed the latest version of Apache Spark. As a first step you’ll test your Spark jobs to see that the upgrade doesn’t have any undesired side effects.
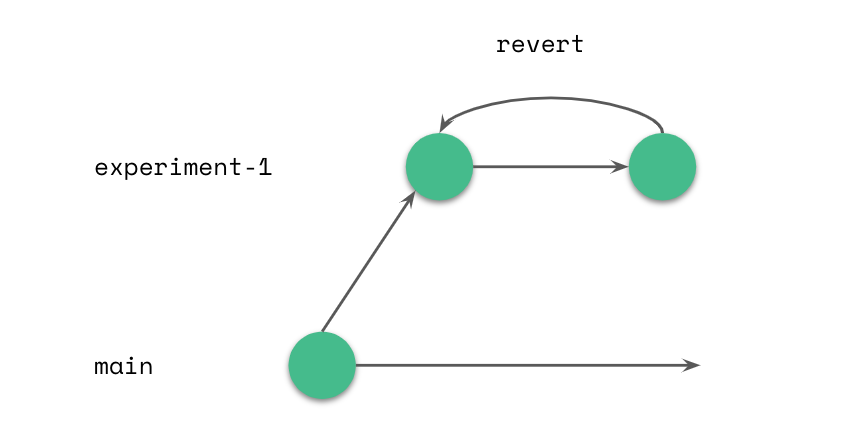
For this purpose, you may create a branch (testing-spark-3.0) which will only be used to test the Spark upgrade, and discarded later. Jobs may run smoothly (the theoretical possibility exists!), or they may fail halfway through, leaving you with some intermediate partitions, data and metadata. In this case, you can simply reset the branch to its original state, without worrying about the intermediate results of your last experiment, and perform another (hopefully successful) test in an isolated branch. Reset actions are atomic and immediate, so no manual cleanup is required.
Once testing is completed, and you have achieved the desired result, you can delete this experimental branch, and all data not used on any other branch will be deleted with it.
Creating a testing branch:
lakectl branch create \
lakefs://example-repo/testing-spark-3 \
--source lakefs://example-repo/main
# output:
# created branch 'testing-spark-3'
Resetting changes to a branch:
lakectl branch reset lakefs://example-repo/testing-spark-3
# are you sure you want to reset all uncommitted changes?: y█
Note lakeFS version <= v0.33.1 uses ‘@’ (instead of ‘/’) as separator between repository and branch.
Example 2: Collaborate & Compare - Which option is better?
Easily compare by testing which one performs better on your data set. Examples may be:
- Different computation tools, e.g Spark vs. Presto
- Different compression algorithms
- Different Spark configurations
- Different code versions of an ETL
Run each experiment on its own independent branch, while the main remains untouched. Once both experiments are done, create a comparison query (using Hive or Presto or any other tool of your choice) to compare data characteristics, performance or any other metric you see fit.
With lakeFS you don’t need to worry about creating data paths for the experiments, copying data, and remembering to delete it. It’s substantially easier to avoid errors and maintain a clean lake after.
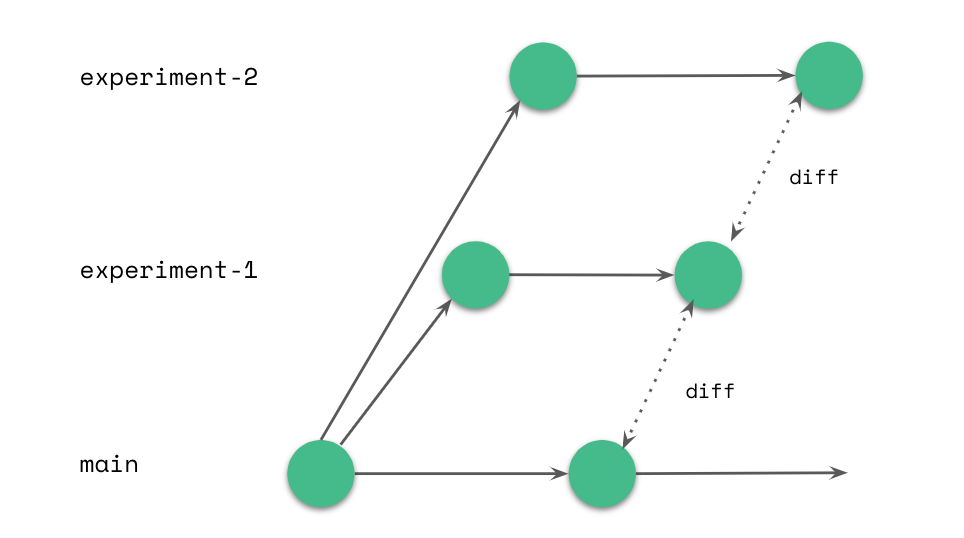
Reading from and comparing branches using Spark:
val dfExperiment1 = sc.read.parquet("s3a://example-repo/experiment-1/events/by-date")
val dfExperiment2 = sc.read.parquet("s3a://example-repo/experiment-2/events/by-date")
dfExperiment1.groupBy("...").count()
dfExperiment2.groupBy("...").count() // now we can compare the properties of the data itself