The Control Plane for AI-Ready Data¶
![]()
lakeFS provides version control over the data lake, using Git-like semantics to create and access data versions. If you know Git, you'll be right at home with lakeFS. You can apply concepts to your data lake such as branching to create an isolated version of the data, committing to create a reproducible point in time, and merging to incorporate your changes in one atomic action.
This same control plane is what makes data safe to hand to AI agents. You can give each agent an isolated, zero-copy branch to work on, keep a human in the loop by gating its changes behind pull requests before they reach production, and audit exactly what every agent did. Teams building retrieval pipelines, training-data workflows, and autonomous data agents use lakeFS to move fast without putting the reliability of production data at risk.
📽️ lakeFS in under 2 minutes
How Do I Get Started?¶
The hands-on quickstart guides you through some core features of lakeFS.
These include branching, merging, and rolling back changes to data.
Tip
You can use the free trial of lakeFS Cloud if you want to try out lakeFS without installing anything.
Key lakeFS Features¶
- It is format-agnostic and works with both structured and unstructured data
- It works with numerous data tools and platforms.
- Your data stays in place, with no need to copy existing data
- It eliminates the need for data duplication using zero-copy branching.
- It maintains high performance over data lakes of any size
- It includes configurable garbage collection capabilities
- It is proven in production and has an active community
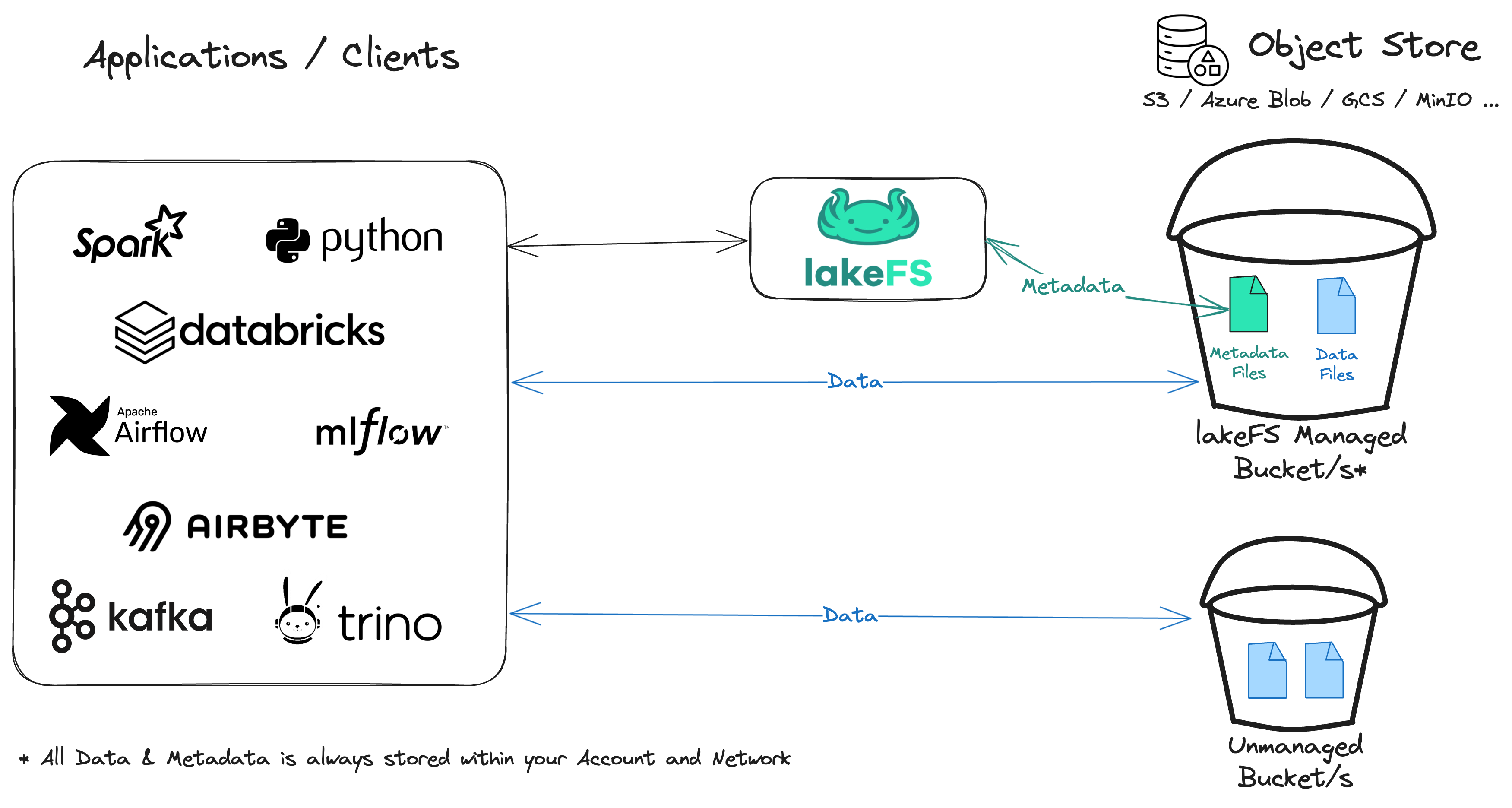
How Does lakeFS Work With Other Tools?¶
lakeFS is an open source project that supports managing data in AWS S3, Azure Blob Storage, Google Cloud Storage (GCS), S3-Compatible storage solutions and even locally mounted directories. It integrates seamlessly with popular data frameworks such as Spark, AWS SageMaker, Pandas, Tensorflow, Polars, HuggingFace Datasets and many more.
With lakeFS, you can use any of the tools and libraries you are used to work with to read and write data directly from a repository.
Example: lakeFS with Pandas
Using this method, lakeFS acts as a metadata layer: it figures out which objects need to be fetched from the underlying storage for that version of the data and then lets the client read or write these files directly from the storage using pre-signed URLs. This allows lakeFS to be both very efficient but also highly secure:
Additionally, lakeFS maintains compatibility with the S3 API to minimize adoption friction. You can use it as a drop-in replacement for S3 from the perspective of any tool interacting with a data lake.
Example
For example, take the common operation of reading unstructured data from the object store using Boto3 (Python):
You can use the same methods and syntax you are already using to read and write data when using a lakeFS repository. This simplifies the adoption of lakeFS - minimal changes are needed to get started, making further changes an incremental process.
lakeFS is Git for Data¶
Git became ubiquitous when it comes to code because it had best supported engineering best practices required by developers, in particular:
- Collaborate during development.
- Reproduce and troubleshoot issues with a given version of the code
- Develop and Test in isolation
- Revert code to a stable version in case of an error
- Continuously integrate and deploy new code (CI/CD)
lakeFS provides these exact benefits, that data practitioners are missing today, and enables them a clear intuitive Git-like interface to easily manage data like they manage code. Through its versioning engine, lakeFS enables the following built-in operations familiar from Git:
- Branch
a consistent copy of a repository, isolated from other branches and their changes. Initial creation of a branch is a metadata operation that does not duplicate objects. - Commit
an immutable checkpoint containing a complete snapshot of a repository. - Merge
performed between two branches — merges atomically update one branch with the changes from another. - Revert
returns a repo to the exact state of a previous commit. - Tag
a pointer to a single immutable commit with a readable, meaningful name. - Hooks
run validations and actions when actions occur (pre-merge,post-create-branch, etc).
Info
See the object model for an in-depth definition of these, and the CLI reference for the full list of commands.
Incorporating these operations into your data and model development provides the same collaboration and organizational benefits you get when managing application code with source control.
How Can lakeFS Help Me?¶
lakeFS helps you maintain a tidy data lake in several ways, including:
Reproducibility: What Did My Data Look Like at a Point In Time?¶
Being able to look at data as it was at a given point is particularly useful in at least two scenarios:
-
Reproducibility of ML experiments
ML experimentation is iterative, requiring the ability to reproduce specific results. With lakeFS, you can version all aspects of an ML experiment, including the data. This enables:
Data Lineage: Track the transformation of data from raw datasets to the final version used in experiments, ensuring transparency and traceability.
Zero-Copy Branching: Minimize storage use by creating lightweight branches of your data, allowing for easy experimentation across different versions.
Easy Integration: Seamlessly integrate with ML tools like MLFlow, linking experiments directly to the exact data versions used, making reproducibility straightforward.
lakeFS enhances your ML workflow by ensuring that all versions of data are easily accessible, traceable, and reproducible.
-
Troubleshooting production problems
In some cases, a user might report inconsistencies, question the accuracy, or simply report data or inference results as incorrect.
Since data continuously changes, it is challenging to understand its state at the time of the error.
With lakeFS you can create a branch from a commit to debug an issue in isolation.
Collaboration during development and training¶
With lakeFS, each member of the team can create their own branch, isolated from other people's changes.
This allows you to iterate on changes to an algorithm or transformation, without stepping on each other's toes. These branches are centralized - they could be shared among users for collaboration, and can even be merged.
With lakeFS you can even open pull requests, allowing you to easily share changes with other members and collaborate on them.
Isolated Dev/Test Environments with zero-copy branching¶
lakeFS makes creating isolated dev/test environments for transformations, model development, parallel experiments, and ETL processes- achieved through the use of zero-copy branches. This enables you to test and validate code changes on production data without impacting it, as well as run analysis and experiments on production data in an isolated clone.
Rollback of Data Changes and Recovery from Data Errors¶
Human error or misconfigurations can lead to erroneous data making its way into production or critical data being accidentally deleted. Traditional backups are often inadequate for recovery in these situations, as they may be outdated and require time-consuming object-level sifting.
With lakeFS, you can avoid these inefficiencies by committing snapshots of data at well-defined times. This allows for instant recovery: simply identify a good historical commit and restore or copy from it with a single operation.
Establishing data quality guarantees - Write-Audit-Publish¶
The best way to deal with mistakes is to avoid them. A data source that is ingested into the lake introducing low-quality data should be blocked before exposure if possible.
With lakeFS, you can achieve this by tying data quality tests to commit and merge operations via lakeFS hooks.
Next Step¶
Compare the lakeFS editions to pick what fits you, run the quickstart locally, or try the fully managed hosted service.