What is lakeFS
lakeFS brings software engineering best practices and applies them to data engineering. Concepts such as Dev/Test environments and CI/CD are harder to implement in data engineering, since the data, and not just the code, should be managed. lakeFS provides version control over the data lake, and uses git-like semantics to create and access those versions, so every engineer feels at home with lakeFS in a few minutes.
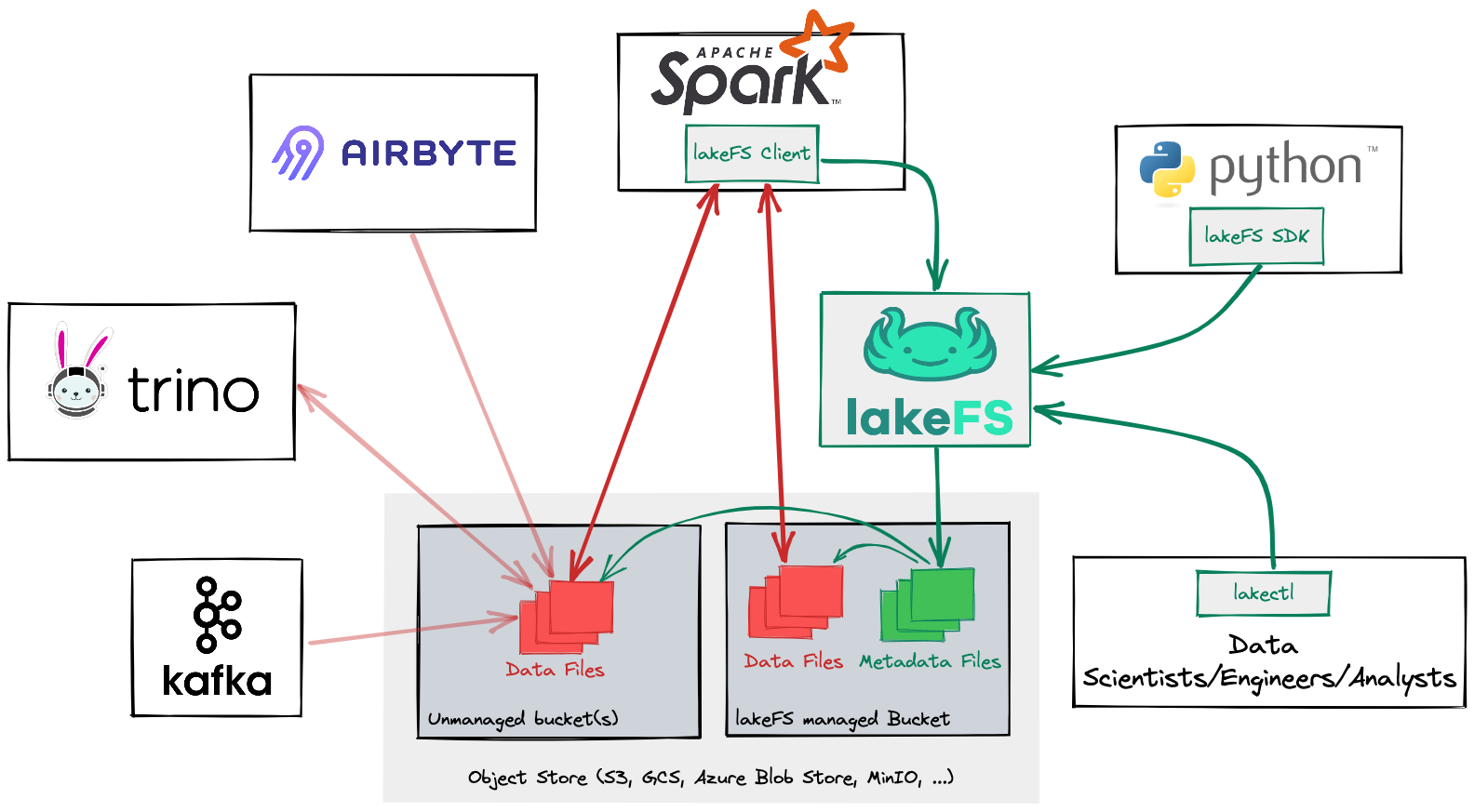
In this reference diagram, lakeFS enables Python applications and Spark jobs with Git-like operations such as branching, committing and rolling back
With lakeFS, you can use concepts such as ״branch״ to create an isolated version of the data, ״commit״, to create a reproducible point it time, and “merge” in order to incorporate your changes in one atomic action.
lakeFS is an open source project that supports managing data in AWS S3, Azure Blob Storage, Google Cloud Storage (GCS) and any other object storage with an S3 interface. It integrates seamlessly with popular data frameworks such as Spark, Hive Metastore, dbt, Trino, Presto, and many others and even features an S3 compatibility layer.
The vision of lakeFS is bringing this functionality across all the data sources in your data pipelines, from analytics databases to key value stores - and to allow one system from which you can easily manage the underlying data in all data stores, with atomic git-like actions.
How do I use lakeFS?
lakeFS maintains compatibility with the S3 API to minimize adoption friction. You can use it as a drop-in replacement for S3 from the perspective of any tool interacting with a data lake.
For example, take the common operation of reading a collection of data from an object storage into a Spark DataFrame. For data outside a lakeFS repo, the code will look like this:
df = spark.read.parquet("s3a://my-bucket/collections/foo/")
After adding the data collections into my-bucket to a repository, the same operation becomes:
df = spark.read.parquet("s3a://my-repo/main-branch/collections/foo/")
You can use the same methods and syntax you are already using to read and write data when using a lakeFS repository. This simplifies the adoption of lakeFS - minimal changes are needed to get started, making further changes an incremental process.
Why is lakeFS the data solution you’ve been missing?
Working with data in a lakeFS repository — as opposed to a bucket — enables simplified workflows when developing data lake pipelines.
lakeFS performs all the following operations safely and efficiently:
- Copying objects between prefixes to promote new data.
- Deleting specific objects to recover from data errors.
- Maintaining auxilliary jobs that populate a development environment with data.
If you spend time performing any of these actions today, adopting lakeFS will speed up your development and deployment cycles, reduce the chance of incorrect data making it into production, and make recovery less painful if it does.
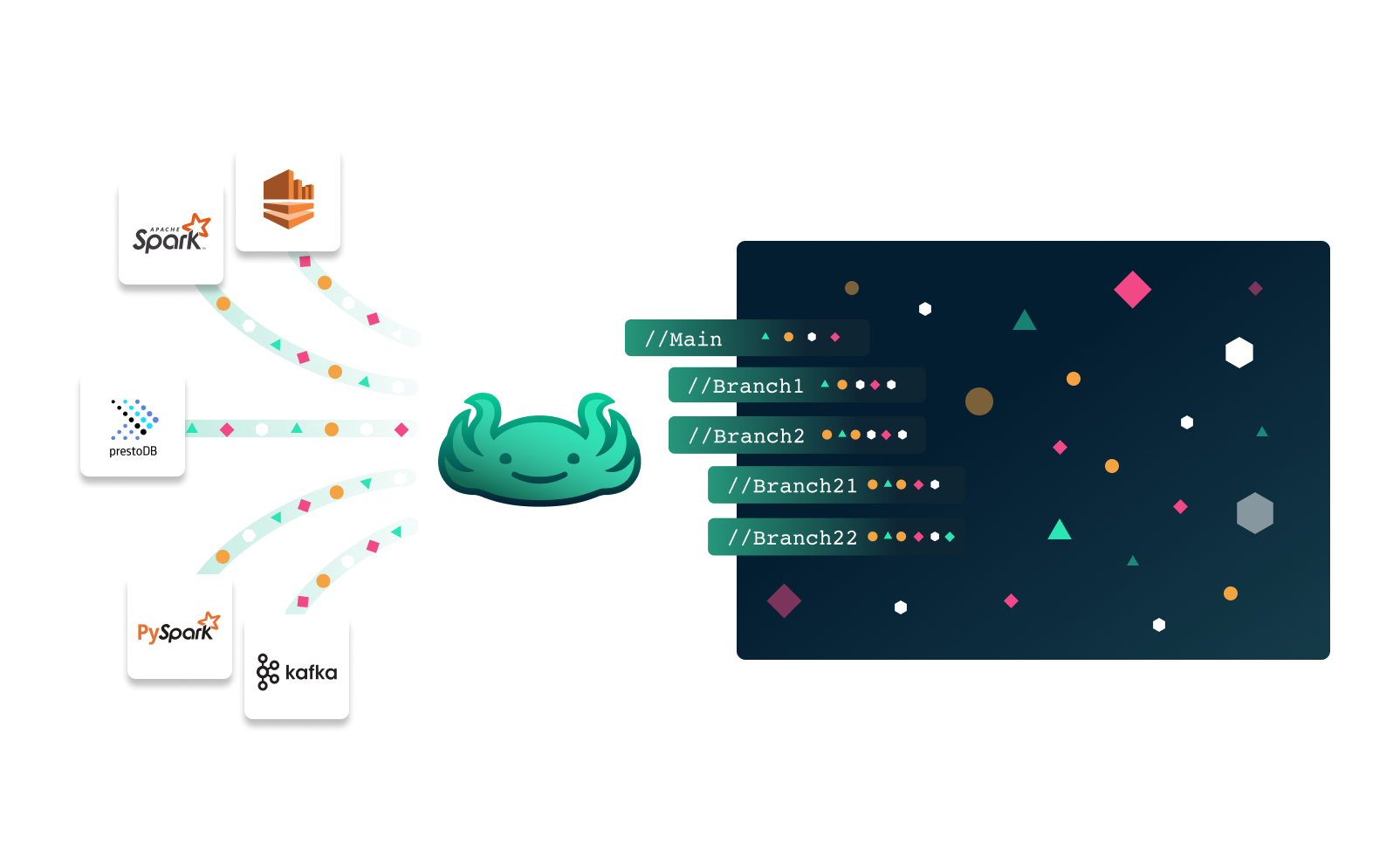
Through its versioning engine, lakeFS enables the following built-in operations familiar from Git:
- branch: a consistent copy of a repository, isolated from other branches and their changes. Initial creation of a branch is a metadata operation that does not duplicate objects.
- commit: an immutable checkpoint containing a complete snapshot of a repository.
- merge: performed between two branches — merges atomically update one branch with the changes from another.
- revert: returns a repo to the exact state of a previous commit.
- tag: a pointer to a single immutable commit with a readable, meaningful name.
See the object model for an in-depth definition of these, and the CLI reference for the full list of commands.
Incorporating these operations into your data lake pipelines provides the same collaboration and organizational benefits you get when managing application code with source control.
The lakeFS promotion workflow
Here’s how lakeFS branches and merges improve the universal process of updating collections with the latest data.

- First, create a new branch from
mainto instantly generate a complete “copy” of your production data. - Apply changes or make updates on the isolated branch to understand their impact prior to exposure.
- And finally, perform a merge from the feature branch back to main to atomically promote the updates into production.
Following this pattern, lakeFS facilitates a streamlined data deployment workflow that consistently produces data assets you can have total confidence in.
What else does lakeFS do?
lakeFS helps you maintain a tidy data lake in several other ways, including:
Recovery from data errors
Human error, misconfiguration, or wide-ranging systematic effects are unavoidable. When they do happen, erroneous data may make it into production or critical data assets might accidentally by deleted.
By their nature, backups are a wrong tool for recovering from such events. Backups are periodic events that are usually not tied to performing erroneous operations. So, they may be out of date, and will require sifting through data at the object level. This process is inefficient and can take hours, days, or in some cases, weeks to complete. By quickly committing entire snapshots of data at well-defined times, recovering data in deletion or corruption events becomes an instant one-line operation with lakeFS: just identify a good historical commit, and then restore to it or copy from it.
Reverting your data lake back to previous version using our command-line tool is explained here.
Data reprocessing and backfills
Occasionally, we might need to reprocess historical data. This can be due to several reasons:
- Implementing new logic.
- Late arriving data that wasn’t included in previous analysis, and need to be backfilled after the fact.
This is tricky as it often involves huge volumes of historical data. In addition, auditing requirements may necessitate keeping the old version of the data.
lakeFS allows you to manage the reprocess on an isolated branch before merging to ensure the reprocessed data is exposed atomically. It also allows you to easily access the different versions of reprocessed data using any tag or a historical commit ID.
Cross-collection consistency guarantees
Data engineers typically need to implement custom logic in scripts to guarantee two or more data assets are updated synchronously. This logic often requires extensive rewrites or periods during which data is unavailable. The lakeFS merge operation from one branch into another removes the need to implement this logic yourself.
Instead, make updates to the desired data assets on a branch and then utilize a lakeFS merge to atomically expose the data to downstream consumers.
To learn more about atomic cross-collection updates, check out this video which describes the concept in more detail.
Troubleshooting production problems
Data engineers are often asked to validate the data. A user might report inconsistencies, question the accuracy, or simply report it to be incorrect. Since the data continuously changes, it is challenging to understand its state at the time of the error.
The best way to investigate is by having a snapshot of the data as close as possible to the time of the error. Once you implement a regular commit cadence in lakeFS, each commit represents an accessible historical snapshot of the data. When needed, you may create a branch from a commit ID to debug an issue in isolation.
To learn more on how to access a specific historical commit in a repository, see our seminal post on data reproducibility.
Establishing data quality guarantees
The best way to deal with mistakes is to avoid them. A data source that is ingested into the lake introducing low-quality data should be blocked before exposure if possible.
With lakeFS, you can achieve this by tying data quality tests to commit and merge operations via lakeFS hooks.
Additional things you should know about lakeFS:
- It is format-agnostic.
- Your data stays in place.
- It minimizes data duplication via a copy-on-write mechanism.
- It maintains high performance over data lakes of any size.
- It includes configurable garbage collection capabilities.
- It is highly available and production-ready.
Downloads
Binary Releases
Binary packages are available for Linux/macOS/Windows on GitHub Releases
Docker Images
The official Docker images are available at https://hub.docker.com/r/treeverse/lakefs
Next steps
Get started and set up lakeFS on your preferred cloud environemnt