Data Model
Overview
Since commits in lakeFS are immutable, they are easy to store on an immutable object store.
Older commits are rarely accessed, while newer commits are accessed very frequently, a tiered storage approach can work very well - The object store is the source of truth, while local disk and even RAM can be used to cache the more frequently accessed ones.
Since they are immutable - once cached, we only need to evict them when space is running out. There’s no complex invalidation that needs to happen.
In terms of storage format, commits are be stored as SSTables, compatible with RocksDB.
SSTables were chosen as a storage format for 3 major reasons:
- Extremely high read throughput on modern hardware: using commits representing a 200m object repository (modeled after the S3 inventory of one of our design partners), we were able to achieve close to 500k random GetObject calls / second. This provides a very high throughput/cost ratio, probably as high as can be achieved on public clouds.
- Being a known storage format means it’s relatively easy to generate and consume. Storing it in the object store makes it accessible to data engineering tools for analysis and distributed computation, effectively reducing the silo effect of storing it in an operational database.
- The SSTable format supports delta encoding for keys which makes them very space efficient for data lakes where many keys share the same common prefixes.
Each lakeFS commit is represented as a set of contiguous, non-overlapping SSTables that make up the entire keyspace of a repository at that commit.
SSTable File Format (“Graveler File”)
lakeFS metadata is encoded into a format called “Graveler” - a standardized way to encode content-addressable key value pairs. This is what a Graveler file looks like:
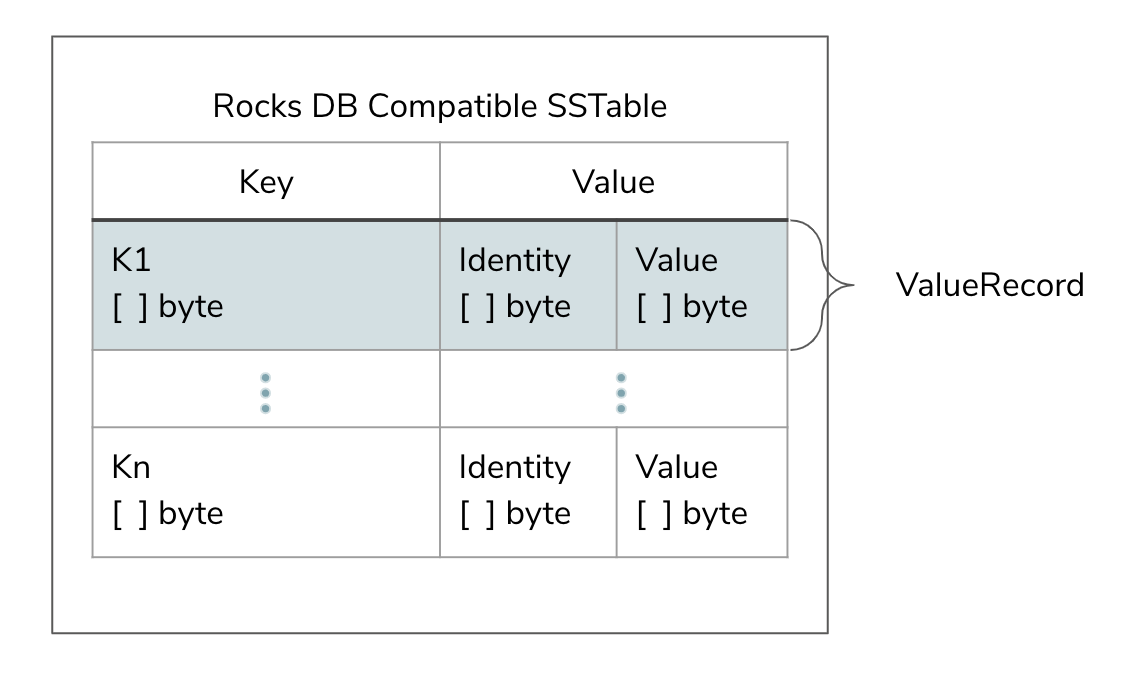
Each Key/Value pair (“ValueRecord”) is constructed of a key, an identity and a value.
A simple identity could be, for example, a sha256 hash of the value’s bytes, but it could be any sequence of bytes that uniquely identifies the value. As far as Graveler is concerned, two ValueRecords are considered identical, if their key and identity fields are equal.
A Graveler file itself is content-addressable, i.e. similarly to Git, the name of the file is its identity. File identity is calculated based on the identity of the ValueRecords the file contains:
valueRecordID = h(h(valueRecord.key) || h(valueRecord.Identity))
fileID = h(valueRecordID1 + … + valueRecordIDN)
Constructing a consistent view of the keyspace (i.e., a commit)
We have 2 additional requirements for the storage format:
- Be space and time efficient when creating a commit - assuming a commit changes a single object out of a billion, we don’t want to write a full snapshot of the entire repository. Ideally, we’ll be able to reuse some data files that haven’t changed to make the commit operations (in both space and time) proportional to the size of the difference as opposed to the total size of the repository.
- Allow an efficient diff between commits which runs in time proportional to the size of their difference and not their absolute sizes.
To support these requirements, we decided to essentially build a 2-layer Merkle tree composed of a set of leaf nodes (“Range”) addressed by their content address, and a “Meta Range”, which is a special range containing all ranges, thus representing an entire consistent view of the keyspace:
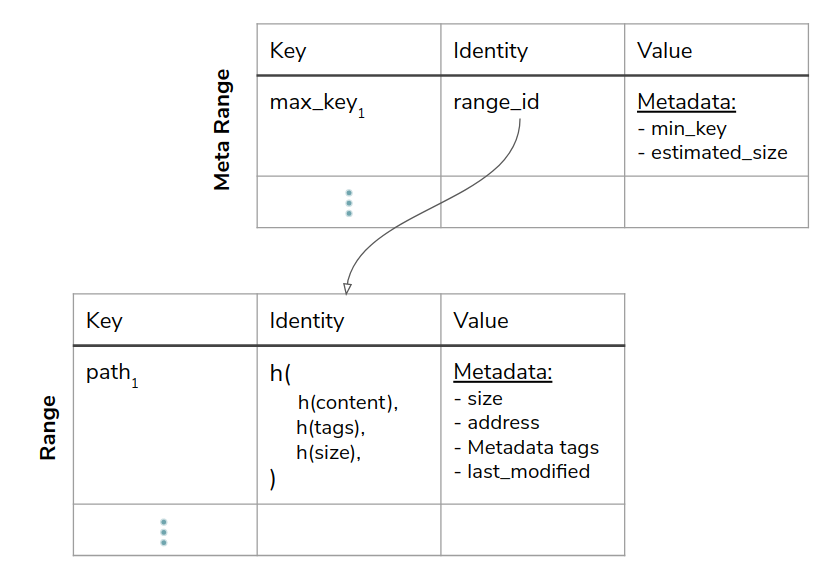
Assuming commit B is derived from commit A, and only changed files in range e-f, it can reuse all ranges except for SSTable #N (the one containing the modified range of keys), which will be recreated with a new hash, representing the state as exists after applying commit B’s changes. This will in turn, also create a new Metarange since its hash is now changed as well (as it is derived from the hash of all contained ranges).
Assuming most commits usually change related objects (i.e. that are likely to share some common prefix), the reuse ratio could be very high. We tested this assumption using S3 inventory from 2 design partners - we partitioned the keyspace to an arbitrary number of simulated blocks and measured their change over time. We saw a daily change rate of about 5-20%.
Given the size of the repositories, it is safe to assume that a single day would translate into multiple commits. At a modest 20 commits per day, a commit is expected to reuse >= 99% of the previous commit blocks, so acceptable in terms of write amplification generated on commit.
On the object store, ranges are stored in the following hierarchy:
<lakefs root>
_lakefs/
<range hash1>
<range hash2>
<range hashN>
...
<metarange hash1>
<metarange hash2>
<metarange hashN>
...
<data object hash1>
<data object hash2>
<data object hashN>
...
Note: this relatively flat structure could be modified in the future: looking at the diagram above, it imposes no real limitations on the depth of the tree. A tree could easily be made recursive by having Meta Ranges point to other Meta Ranges - and still provide all the same characteristics. For simplicity, we decided to start with a fixed 2-level hierarchy.
Representing references and uncommitted data
Unlike committed data which is immutable, uncommitted (or “staged”) data experiences frequent random writes and is very mutable in nature. This is also true for “refs” - in particular, branches, which are simply pointers to an underlying commit, are modified frequently: on every commit or merge operation.
Both these types of data are not only mutable, but also require strong consistency guarantees while also being fault tolerant. If we can’t access the current pointer of the main branch, a big portion of the system is essentially down.
Luckily, this is also much smaller data, compared to the committed dataset.
References and uncommitted data are currently stored on PostgreSQL for its strong consistency and transactional guarantees.
In the future we plan on eliminating the need for an RDBMS by embedding Raft to replicate these writes across a cluster of machines, with the data itself being stored in RocksDB. To make operations easier, the replicated RocksDB database will be periodically snapshotted to the underlying object store.
For extremely large installations ( >= millions of read/write operations per second), it will be possible to utilize multi-Raft to shard references across a wider fleet of machines.