What is lakeFS
lakeFS is an open source platform that delivers resilience and manageability to object-storage based data lakes.
With lakeFS you can build repeatable, atomic and versioned data lake operations - from complex ETL jobs to data science and analytics.
lakeFS supports AWS S3, Azure Blob Storage and Google Cloud Storage (GCS) as its underlying storage service. It is API compatible with S3 and works seamlessly with all modern data frameworks such as Spark, Hive, AWS Athena, Presto, etc.
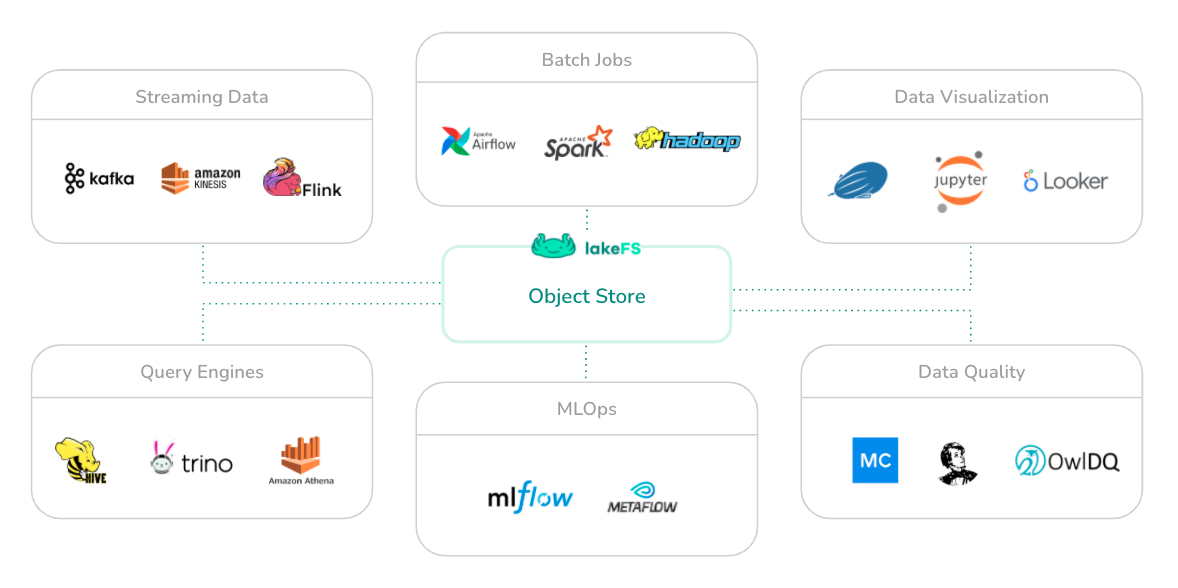
Why you need lakeFS and what it can do
lakeFS provides a Git-like branching and committing model that scales to exabytes of data by utilizing S3, GCS, or Azure Blob for storage.
This branching model makes your data lake ACID compliant by allowing changes to happen in isolated branches that can be created, merged and rolled back atomically and instantly.
Since lakeFS is compatible with the S3 API, all popular applications will work without modification, by simply adding the branch name to the object path:

Use-cases:
lakeFS enhances processing workflows at each step of the data lifecycle:
In Development
- Experiment - try new tools, upgrade versions, and evaluate code changes in isolation. By creating a branch of the data you get an isolated snapshot to run experiments over, while others are not exposed. Compare between branches with different experiments or to the main branch of the repository to understand a change’s impact.
- Debug - checkout specific commits in a repository’s commit history to materialize consistent, historical versions of your data. See the exact state of your data at the point-in-time of an error to understand its root cause.
- Collaborate - avoid managing data access at the two extremes of either 1) treating your data lake like a shared folder or 2) creating multiple copies of the data to safely collaborate. Instead, leverage isolated branches managed by metadata (not copies of files) to work in parallel.
During Deployment
- Version Control - deploy data safely with CI/CD workflows borrowed from software engineering best practices. Ingest new data onto an isolated branch, perform data validations, then add to production through a merge operation.
- Test - define pre-merge and pre-commit hooks to run tests that enforce schema and validate properties of the data to catch issues before they reach production.
In Production
- Roll Back - recover from errors by instantly reverting data to a former, consistent snapshot of the data lake. Choose any commit in a repository’s commit history to revert in one atomic action.
- Troubleshoot - investigate production errors by starting with a snapshot of the inputs to the failed process. Spend less time re-creating the state of datasets at the time of failure, and more time finding the solution.
- Cross-collection Consistency - provide consumers multiple synchronized collections of data in one atomic, revertable action. Using branches, writers provide consistency guarantees across different logical collections - merging to the main branch only after all relevant datasets have been created or updated successfully.
Downloads
Binary Releases
Binary packages are available for Linux/macOS/Windows on GitHub Releases
Docker Images
Official Docker images are available at https://hub.docker.com/r/treeverse/lakefs
Next steps
Get started and set up lakeFS on your preferred cloud environemnt